
Abstract
This report examines the construction and optimization of a scalable and cost-efficient serverless data lake on cloud platforms. Serverless data lakes provide organizations with a flexible and economical solution for managing large volumes of data without the complexities of traditional infrastructure management.
This report discusses the benefits of serverless architectures, implementation strategies, best practices for maximizing efficiency and security in data handling, and the future implications of adopting this technology.
Additionally, this report examines various cloud provider solutions such as AWS, Azure, and Google Cloud, addressing their unique capabilities. By following their best practices and taking advantage of serverless data lakes, organizations can effortlessly improve their data management and analytics capabilities while reducing costs and operational overhead.
Keywords: Serverless data lake, cloud computing, cost efficiency, data management, scalability
Background
The growth of data in various sectors has necessitated more viable and reliable storage solutions that can efficiently handle vast amounts of information. Traditional data lakes require significant infrastructure management, leading to increased operational costs and complexity.
In contrast, serverless data lakes offer a streamlined approach by allowing cloud providers to manage backend resources dynamically. This report delves into the characteristics, advantages, and implementation strategies of serverless data lakes.
Introduction
Serverless computing is a transformative model in cloud architecture, particularly for data storage and processing. A serverless data lake is a cloud-based solution that enables organizations to store and analyze large datasets without the need for dedicated servers or extensive infrastructure management.
This model is appealing due to its cost efficiency, automatic scaling, and reduced management overhead. As organizations increasingly rely on data-driven decision-making, understanding how to implement a serverless data lake effectively becomes crucial.
Traditional data lakes require frequent monitoring and manual scaling; however, serverless data lakes dynamically allocate resources based on demand, ensuring scalability and cost efficiency. For example, a retail company experiencing seasonal spikes in sales data can rely on serverless architecture to automatically scale resources during peak times and scale down during off-peak periods, optimizing costs without compromising performance.
This flexibility makes serverless data lakes particularly advantageous for industries with variable workloads.
With serverless architectures, businesses can redirect their focus from managing hardware to generating actionable insights. This shift allows organizations to allocate more resources to strategic initiatives such as predictive analytics, customer segmentation, and machine learning applications.
Serverless systems' ability to integrate seamlessly with advanced analytical tools accelerates the process of turning raw data into valuable insights, enhancing decision-making processes across sectors.
This paper quantifies the architecture and benefits of serverless data lakes, explores their implementation across major cloud providers, and provides best practices for optimization to unlock their full potential.
Benefits of Serverless Data Lakes
Cost Efficiency
One of the primary advantages of serverless data lakes is their cost-effective billing model. Organizations only pay for the resources they utilize, making it ideal for fluctuating workloads (1). This prevents unnecessary expenditures associated with underutilized resources.
Automatic Scaling
Serverless architectures automatically adjust resource allocation based on workload demands. Unlike traditional systems that require manual scaling, serverless solutions can efficiently handle variable loads. This flexibility is essential for organizations that experience unpredictable data spikes.
Reduced Management Overhead
By leveraging cloud providers' capabilities, organizations can focus on deriving insights from their data rather than managing infrastructure. This shift reduces the operational burden associated with maintenance and upgrades.
Faster Time to Insight
The streamlined nature of serverless architectures accelerates the process of obtaining insights from data. Organizations can bypass typical setup and maintenance delays associated with traditional systems. This rapid access to insights facilitates timely decision-making and enhances competitive advantage.
Enhanced Collaboration
Serverless data lakes foster collaboration among teams by enabling easy access to shared datasets without the need for complex configurations or permissions management (2). This collaborative environment promotes innovation and accelerates project timelines.
Implementing a Serverless Data Lake
Choosing the Right Cloud Provider
Major cloud service providers offer various serverless data lake solutions. For instance:
- AWS: Lake Formation with Amazon S3
- Azure: Blob Storage
- Google Cloud: BigQuery
AWS offers Amazon S3 and Lake Formation, which allow seamless integration with other AWS services such as Glue for ETL tasks and Athena for querying. Azure utilizes Blob Storage, which is optimized for scalable storage and supports tools like Azure Synapse Analytics for advanced data processing. Google Cloud provides BigQuery, a serverless data warehouse that excels in handling large-scale analytics.
Organizations should select a provider based on their specific data processing needs and security requirements (1).
Storage Setup
Data storage is fundamental to any data lake's architecture. Providers like Amazon S3, Azure Blob Storage, and Google Cloud Storage support various data types—unstructured, semi-structured, and structured—facilitating diverse analytics applications. The ability to store petabytes of data allows organizations to handle extensive datasets efficiently.
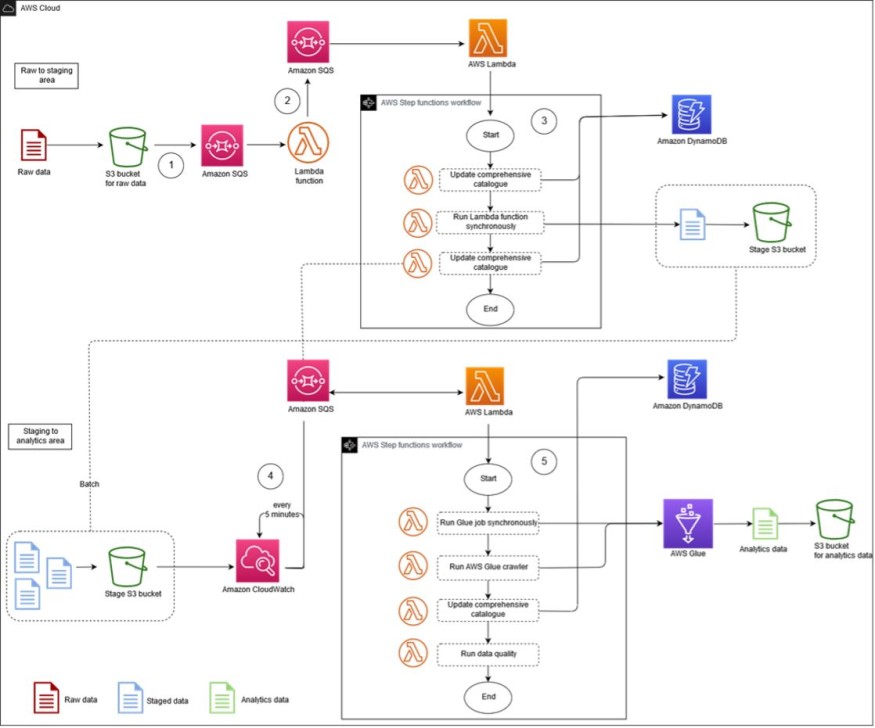
Core storage options include Amazon S3, Azure Blob Storage, and Google Cloud Storage, which support unstructured, semi-structured, and structured data types. These solutions are designed to integrate seamlessly with analytical tools.
For example, Amazon S3 can store logs, media files, and IoT data, while its intelligent tiering feature automatically optimizes storage costs by moving less frequently accessed data to lower-cost storage classes.
Data Processing Options
Cloud services facilitate efficient data processing in serverless environments. Tools such as AWS Glue and Athena for ETL processes or Google BigQuery for querying enhance operational scalability while optimizing performance. These tools enable organizations to perform complex queries without the overhead of managing physical servers.
Tools such as AWS Glue and Athena, Azure Synapse, and Google BigQuery enable efficient data querying and processing within the data lake environment. AWS Glue, for example, automates ETL workflows, allowing businesses to clean and prepare data for analysis.
Azure Synapse offers an integrated analytics service combining big data and data warehousing, which is suitable for companies handling real-time processing.
Google BigQuery's serverless model supports machine learning integration, enabling advanced data-driven insights for e-commerce platforms analyzing customer behaviors.
Security and Compliance
Security measures are critical in managing a serverless data lake. Implementing encryption and Identity and Access Management (IAM) ensures compliance with regulations like GDPR or HIPAA (2).
Organizations must prioritize security protocols to protect sensitive information while maintaining accessibility for authorized users.
Serverless Data Lakes: Best Practices for Implementation
To maximize the benefits of serverless data lakes, organizations should consider the following best practices:
- Optimize Data Partitioning: Implementing partitions based on parameters such as date or region can enhance efficiency. Different processes and users can access various sections of data simultaneously, reducing costs associated with querying large datasets.
- Use Lifecycle Policies: Most cloud vendors have lifecycle policies to transition less active data to cheaper storage options quickly. For instance, AWS offers S3 Glacier, designed for archival storage at minimal costs for less active data (2).
- Implement Role-Based Access Control (RBAC): Regularly reviewing access rights ensures that only authorized personnel have access to sensitive information. Over time, some employees may no longer need certain access rights; thus, periodic checks are necessary.
- Utilize Serverless ETL Tools: Automation of ETL processes simplifies the cleaning, preparation, and analysis of data. Tools like AWS Glue and Google Dataflow are gaining popularity due to their ability to streamline workflows effectively.
Conclusion
Serverless data lakes represent a proper and reliable solution for organizations seeking efficient ways to manage large datasets without the complexities of traditional infrastructure.
With the use of cost-effective models, automatic scaling features, reduced management overheads, enhanced collaboration capabilities, and optimized processing tools, businesses can significantly improve their operations.
However, challenges related to security and compliance must be addressed through best practices in implementation. As organizations continue to make use of this technology, serverless data lakes will play a considerable role in shaping the future of data management.
References
- Baldini, Ioana & Castro, Paul & Chang, Kerry & Cheng, Perry & Fink, Stephen & Isahagian, Vatche & Mitchell, Nick & Muthusamy, Vinod & Rabbah, Rodric & Slominski, Aleksander & Suter, Philippe. (2017). Serverless Computing: Current Trends and Open Problems. 10.1007/978-981-10-5026-8_1. https://link.springer.com/chapter/10.1007/978-981-10-5026-8_1
- Prescriptive guidance provided by Amazon. Deploy and manage a serverless data lake on the AWS Cloud by using infrastructure as code. https://docs.aws.amazon.com/prescriptive-guidance/latest/patterns/deploy-and-manage-a-serverless-data-lake-on-the-aws-cloud-by-using-infrastructure-as-code.html
About the Author

Kiran is a Principal Solutions Architect at Amazon Web Services (AWS) who leverages over 17 years of experience in cloud computing and machine learning to drive sustainable, AI-powered innovations. He is known for his expertise in migration & modernization, data & analytics, AI and ML, security, and other cutting-edge technologies. In his current capacity, Kiran works closely with AWS's Global Strategic SI (System Integrator) partners. He works diligently to create and implement successful cloud strategies that allow these partners to get the full benefits of cloud technology. Kiran has spoken at various Partner Summits, AWS events, and AWS Summits and is an Amazon Senior Speaker Certified speaker.
© 2026 ScienceTimes.com All rights reserved. Do not reproduce without permission. The window to the world of Science Times.












