
Users today demand immediate access to data. Whether they're involved in e-commerce, media streaming, or working with large content repositories, any delay can lead to frustration and drop-offs. This significantly strains systems that manage intricate, deeply nested, and overlapping category structures. Slow response times degrade user experience and have a direct impact on revenue.
Picture this: an online electronics store offering thousands of products across categories like "Laptops," "Gaming Laptops," "Business Laptops," and "Accessories," each containing overlapping products. The system must retrieve and organize these products efficiently. Without optimization, several issues arise:
- Slow Load Times: Retrieving products from multiple overlapping and nested categories takes several seconds.
- Duplicate Products: Products that appear in multiple categories are shown more than once, which can seem odd or redundant.
- Poor Scrolling Performance: Loading numerous items without efficient sorting slows down page scrolling.
A few years ago, such delays were much more common and tolerated by users. However, expectations have shifted, with platforms like Netflix and Amazon setting high standards for speed and responsiveness. Today, as studies consistently show, users demand instantaneous results:
- Google reports that the probability of a user leaving a site increases by 32% if the page load time goes from 1 to 3 seconds and jumps to 90% if it reaches 5 seconds.
- Amazon estimates that a 100-millisecond delay in page load time can cost them 1% in sales.
- Walmart found that improving load times by just one second increased conversion rates by up to 2%.
In e-commerce, every second counts. Users are quick to abandon slow sites, often moving to competitors. For businesses, this means lost sales and decreased engagement.
Developer Challenges
Handling simple catalogs—like a store with 100 products or a straightforward structure—may not cause much trouble. However, as catalogs grow more complex, with hundreds or thousands of products across multiple nested categories, a forehead approach leads to poor performance and money loss.
For example, when a user requests to view all products in a category like "Gaming Laptops," the system faces several challenges:
- Complex Queries: The system needs to pull products from the main category and all related subcategories.
- Recursive Processing: Fetching products from nested categories involves recursive database calls, which increases system load.
- Deduplication: Products appearing in multiple categories create duplicates that need to be filtered out, adding complexity.
- Sorting and Pagination: After retrieval, products need to be sorted and paginated, putting further strain on the system.
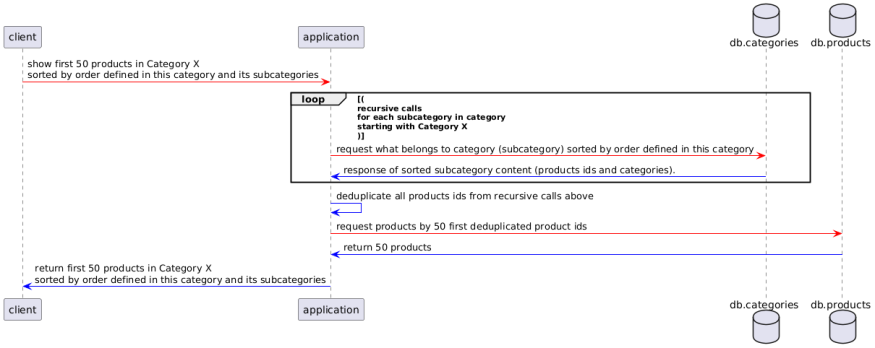
All these steps add up, making the process resource-heavy, slowing down performance, and ultimately harming the user experience. With no clear industry standard or ready-made solution, developers are left with tough challenges to solve. The possible solution that could benefit developers worldwide was offered by Egor Grushin, a seasoned software engineer and Hackernoon contributor.
Applying Graph Theory
To address these issues, an innovative method using graph theory, specifically transitive closures, along with advanced indexing techniques, provides a solution.
The key to this method is representing the catalog system as a directed acyclic graph (DAG):
- Vertices represent products and categories.
- Edges show the relationships between categories and products.
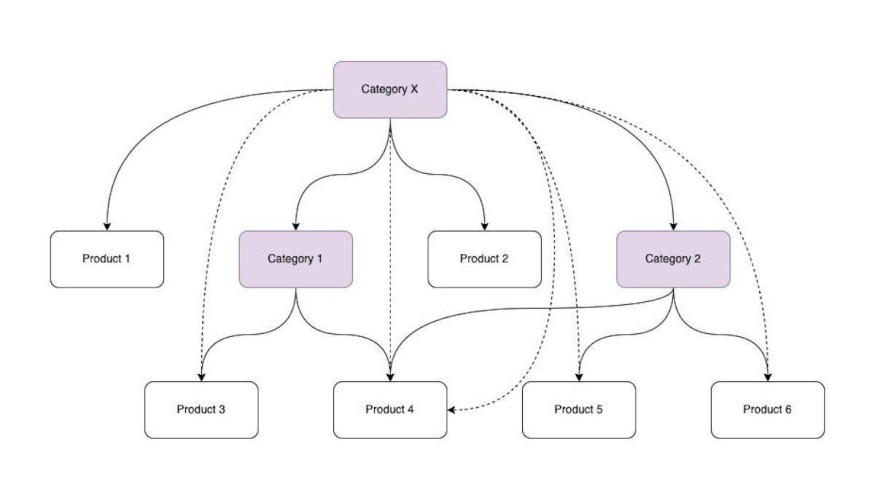
This catalog structure helps pre-map all possible paths between categories and products. This lets the system understand direct and indirect relationships without performing complicated queries during runtime.
Using transitive closures, a developer can calculate all indirect relationships between nodes in the graph, respecting their order. This means that if Category A includes Category B, and Category B includes Product X, the system knows that Product X is also included in Category A through this indirect path.
This graph is used to mark products with additional data, which helps avoid complex queries:
- The data is already deduplicated.
- Since all relationships are known in advance, the system no longer needs to perform recursive database calls.
- Since all the connections have been built in advance, their order is statically determined, meaning that on-the-fly sorting is no longer required.
- Retrieving all products for a category is reduced to a single, efficient database query.
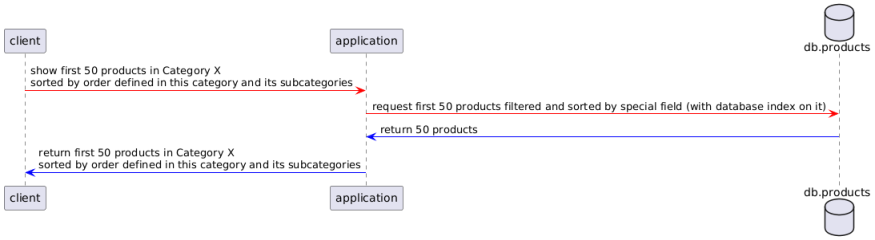
Creating a Dedicated Service
Catalogs constantly change as products and categories are added, removed, or updated. To manage this, a dedicated microservice independently handles the graph of product-category relationships, ensuring the system remains scalable and modular.
When changes occur, the microservice updates the graph and recalculates transitive closures without impacting the main system's entities. This way, dynamic updates are managed efficiently, keeping everything running smoothly.
This step-by-step guide helps product teams implement the solution, making adoption and integration into the systems easier.
Impact
This approach can potentially become a fully reusable solution, freeing developers of complex catalogs worldwide from repeatedly solving the same problem. Users experience faster load times and smoother navigation, which boosts satisfaction and engagement. The system efficiently manages large, intricate catalogs and maintains strong performance even as data grows.
For businesses, this enhanced performance can lead to higher conversion rates and improved customer retention. A faster, more responsive system keeps users coming back, directly increasing revenue and helping businesses meet the high industry standards for responsiveness set by FAANG.
Beyond E-commerce
While this method was developed to solve challenges in e-commerce, its applications reach beyond that. It can be used in other industries that deal with complex, nested data:
- Content Management Systems: Organizing articles, media, or documents across multiple categories and tags.
- Logistics and Supply Chain: Tracking items across different stages and locations within a network.
- Organizational Structures: Mapping relationships within large organizations that have overlapping departments and roles.
This approach is beneficial for any system that requires efficient retrieval of items from overlapping or nested categories.
Conclusion
As industries expand and data becomes more intricate, such approaches ensure that systems remain responsive and users stay satisfied. Performance is key, especially as catalogs grow increasingly complex.
Graph theory provides an alternative solution to a common problem faced by developers and architects. This approach frees teams from the need to repeatedly address the same issue without a widely adopted solution in place. Moreover, it addresses long-standing challenges and offers a scalable solution that allows companies to meet demands and increase performance.
By representing catalogs as directed acyclic graphs and using transitive closures, systems can avoid costly recursive queries, deduplication, and on-the-fly sorting. The result: faster load times, better scalability, and an enhanced user experience.
© 2026 ScienceTimes.com All rights reserved. Do not reproduce without permission. The window to the world of Science Times.











