Data quality serves as the foundation for the success of any data engineering platform. In the context of data, quality is defined by key attributes such as accuracy, completeness, integrity, conformity, and consistency. High-quality data is essential for enforcing effective data governance, supporting informed business decisions, and ensuring the reliability of operational processes. When data quality is compromised, the repercussions can be significant. Organizations that act based on incorrect data may suffer from one or more of the following negative outcomes:
- Misguided business decisions: poor data can lead to inaccurate insights, resulting in strategic errors.
- Reputation damage: incorrect reporting erodes trust with stakeholders and customers.
- Financial losses: resources are wasted on correcting errors or dealing with inefficiencies.
- Reduced return on investment (ROI): unreliable data undermines the value of investments in technology and processes.
- Customer dissatisfaction: errors in customer data can lead to negative experiences, damaging loyalty.
- Missed opportunities: inability to compete effectively due to flawed or incomplete data.
Achieving data quality is both a necessity and sometimes a challenge. Effective data quality management, therefore, isn't just a goal—it's a prerequisite for sustainable success. Addressing these issues involves robust data validation frameworks, enforcing data governance practices, and leveraging automated solutions to mitigate inaccuracies and inconsistencies at scale.
I recently completed a data engineering project for a leading mobile device protection company in the United States, a key player in the insurance industry. The organization processes millions of subscriber records across its platform, sourced from prominent mobility carriers and vendors. Its operations rely heavily on data quality to ensure timely enrollment of subscribers, accurate claim processing, efficient customer communications, predictive analytics for customer purchase plans and device failures, and accurate agent commission disbursal. The project underscored the importance of data integrity in delivering service excellence. However, we faced significant gaps between the ideal standards of data quality management and the reality, which posed challenges to meeting the organization's critical service objectives.
Data Quality Challenges
In our cloud-based data engineering system, managing inbound data, such as subscriber records from carrier files, poses significant challenges. The frequent and inconsistent changes to subscriber records—many of which stem from data quality issues rather than genuine business updates—create a chaotic environment for identifying unique subscribers and tracking daily profile changes. The specific inbound challenges we typically encounter include:
- Frequent subscriber record changes: iterative modifications in the inbound carrier files often lack genuine business rationale, leading to difficulties in tracking unique subscriber identities and identifying valid profile updates.
- Program assignment errors: customer-selected programs cannot be assigned to subscriptions due to invalid subscription fee formats. Since program allocation is fee-dependent, this disrupts the workflow and impacts customer satisfaction.
- Special character interference: special characters in data fields from inbound files lead to incorrect data interpretation. Identifying and addressing these patterns is highly complex and resource-intensive.
- Sales commission discrepancies: monthly sales commissions are calculated based on enrollments. Missing or inconsistent sales representative details make it impossible to compute commissions accurately.
- Equipment failure prediction errors: missing or incorrect equipment details hinder accurate predictions for equipment failures, negatively affecting operational efficiency and decision-making.
Outbound data is associated with its own unique challenges. Our outbound system generates critical communications, such as white letters for enrollment, subscription renewals, and subscription cancellations. However, these rely heavily on data sourced from previous inbound workflows, where poor data quality exacerbates issues such as:
- Missing mandatory data: key fields, though not required for inbound processing, are mandatory for outbound workflows. Missing data in outbound files renders the generated output invalid.
- Delayed data updates: carriers often update missing or incorrect data days after the outbound process extracts the data. This results in incomplete communications, necessitating manual intervention to fix errors.
- Business and legal risks: delays or missing letters for renewals and cancellations can lead to significant customer dissatisfaction and potential litigation.
These challenges highlight the critical need for robust data quality management practices, automated validation mechanisms, and comprehensive data governance frameworks to ensure smooth operations, accurate reporting, and timely communication.
Data Quality Framework: Solution and Implementation
Addressing data quality challenges requires collaboration with a wide range of stakeholders, including partner teams, business leaders, data scientists, data analysts, and data engineers. While traditional approaches like anomaly detection, validation, and reporting help identify issues, they often fall short of resolving them effectively. To achieve transformative results, we implemented a self-healing data quality enforcement framework, leveraging Artificial Intelligence/Machine Learning (AI/ML) capabilities for automated anomaly detection and resolution.
The framework we developed integrates advanced AI and ML models trained on historical data quality issues and patterns. This system is designed not only to detect anomalies but also to categorize, predict, and resolve them through automated mechanisms. As the illustration below shows, the supervised model of anomaly detection provided high accuracy for the challenges.
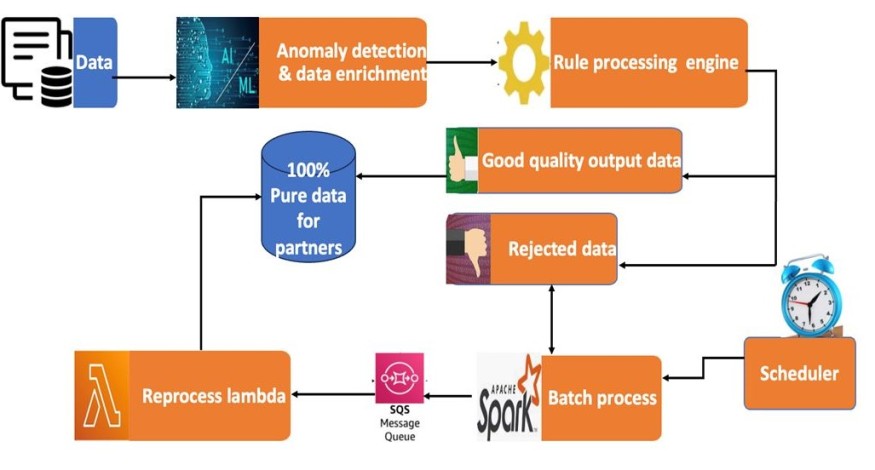
To implement the design, we began by ingesting inbound and outbound data from multiple sources into the AI/ML-enabled anomaly detection system. The system identifies inconsistencies, missing fields, and incorrect values, categorizing them into specific buckets for targeted resolution and reporting. We then used predictive modeling to enrich the data, using ML models to predict missing or incorrect values by analyzing historical patterns. At this stage, missing fields are enriched using alternative, dependent systems, leveraging Application Programming Interfaces (APIs) to fetch transactional data or referencing configuration and lookup tables for setup data.
For complex scenarios, a robust rule-processing engine executes predefined business rules on the preprocessed data to handle complex use cases. For example, if certain subscription data fields are missing in the carrier's input file, the framework dynamically retrieves these values from dependent systems to ensure data completeness. Data anomalies that cannot be resolved immediately are handled through a Service Level Agreement (SLA)-driven auto-healing process. The rejected data are reprocessed daily using batch jobs written in Apache Spark and Scala, which push the refined data to Amazon Simple Queue Service (SQS).
Finally, a custom Amazon Web Services (AWS) Lambda function validates reprocessed data against updated source systems. If missing mandatory fields become available at a later date, the process updates the rejected records and reintegrates them into the data pipeline for subsequent processing.
Key Results
The AI/ML-enabled data quality framework with self-healing capabilities seamlessly integrated into our system, combining AI/ML models, rule-based engines, and cloud services to address data quality issues across all stages of the data lifecycle. Equally important were the meaningful results it achieved in terms of improved data integrity, increased business satisfaction, operational efficiency, and business value. By enhancing the prediction and correction of missing or inconsistent data, the new framework ensures accuracy and reliability. Additionally, automated processes ensure quicker anomaly resolution and improve overall system performance. The implementation of the data quality solution delivered 100% data quality across the organization. By automating tasks that previously required the efforts of four team members, the solution significantly reduced manual intervention, expedited issue resolution, and generated annual cost savings of $450,000 for the organization.
The results generated with this new solution enabled accurate reporting, better decision-making, and timely customer communication, avoiding potential legal and financial risks for our organization. This holistic framework demonstrates a significant leap forward in ensuring data quality with a scalable and sustainable approach that evolves with business needs.

Sanjay Puthenpariyarath is recognized as an expert data engineer for his original contributions and success in designing and implementing scalable data architecture solutions for Fortune 500 companies in the banking, telecom, and e-commerce industries. For nearly two decades, he has specialized in big data processing, data pipeline development, cloud data engineering, data migration, and database performance tuning, using cutting-edge technologies that have enabled him to optimize data workflows and achieve significant improvements in financial and operational outcomes. Sanjay received a Bachelor of Engineering degree in Electronics and Communication Engineering from Anna University, India, and earned a Master of Science degree in Information Technology from the University of Massachusetts, Lowell (US). As a senior leader, he enjoys mentoring data engineers, promoting data-driven organizational cultures, and delivering complex projects on time and within budget.
© 2026 ScienceTimes.com All rights reserved. Do not reproduce without permission. The window to the world of Science Times.










